DB 스키마에도 git이 필요할까요?
이 글은 직무 통합 과정에서 백엔드 실무를 맡게 된 프론트엔드 개발자가 실제 작업을 부딪히며 배운 것들을 주제 단위로 정리하는 시리즈입니다. 낯선 개념을 이미 아는 개념에 대응시키는 방식으로 씁니다.
컬럼 하나를 추가하려고 보니
ALTER TABLE을 어디에 적어야 하는지부터 막혔습니다. DB 콘솔에서 직접 실행하는 게 아니라 SQL 파일을 레포에 커밋한다는 것, 그 파일들이 순서대로 쌓여서 지금의 스키마를 만든다는 것 — 그러니까 스키마에 git이 하나 더 있다는 것을 그때 알았습니다. 그리고 그 git의 규칙을 어겨서 CI를 한 번 깨뜨려 봤습니다.살아 있는 데이터 위에서 스키마를 바꾸는 일은 어떻게 관리될까요?
이 글에서 다루는 내용
이 글은 시리즈에서 처음으로 프론트엔드에 대응물이 없는 문제를 다룹니다. 클라이언트의 상태는 새로고침하면 사라지지만 서버의 데이터는 남아서 움직여야 합니다. 그 위에서 스키마를 바꾸는 도구(마이그레이션)의 핵심 개념 — changelog와 baseline — 을 git에 대응시켜 이해하고, 실제로 데인 함정 하나와, 변경 이력을 자동으로 남기는 audit 테이블까지 정리합니다.
1. 프론트엔드에는 없는 문제입니다
이 시리즈 내내 프론트엔드 대응물을 찾아왔는데, 이번 주제는 정직하게 말해서 대응물이 없습니다. 프론트엔드의 상태는 본질적으로 휘발됩니다 — 스토어 구조를 바꾸면 새로고침 한 번으로 모두가 새 구조에서 시작합니다. 로컬 스토리지 정도가 예외지만 그마저 "깨지면 지우고 다시"가 통하는 세계입니다. 가장 가까운 진짜 예외는 IndexedDB입니다 — 스키마 버전과 업그레이드 콜백(onupgradeneeded)을 갖고 있어서 오프라인 우선 앱이라면 실제로 마이그레이션 코드를 쓰게 됩니다. 다만 그것도 기기 하나의 데이터일 뿐, 모두가 공유하는 단 하나의 데이터베이스를 옮기는 일과는 무게가 다릅니다.
서버의 DB는 다릅니다. 데이터가 살아남는 것 자체가 존재 이유입니다. 코드는 배포로 통째로 갈아끼울 수 있지만 데이터는 갈아끼우는 게 아니라 옮겨야 합니다. 스키마를 바꾼다는 것은 곧 "지금 쌓여 있는 데이터를 어떻게 새 구조로 데려가는가"의 문제고, 게다가 그 일은 개발·스테이징·프로덕션과 모든 동료의 로컬 DB에서 같은 순서로 재현되어야 합니다.
"같은 변경이 어디서나 같은 순서로 재현되어야 한다" — 이 문장을 다시 읽어 보면 답이 이미 들어 있습니다. 우리가 코드에서 이 문제를 푸는 도구를 이미 알고 있기 때문입니다.
Recap
프론트엔드 상태는 휘발되지만 서버의 데이터는 살아남아야 하고, 스키마 변경은 쌓인 데이터를 새 구조로 데려가는 일입니다. 그 변경은 모든 환경에서 같은 순서로 재현되어야 하며, 이 요구사항은 우리가 코드에서 이미 쓰는 도구 하나를 정확히 가리킵니다.
2. changelog는 커밋, baseline은 스쿼시
그 도구가 마이그레이션 도구입니다. Liquibase나 Flyway 같은 도구들의 핵심 아이디어는 하나입니다 — DB용 git.
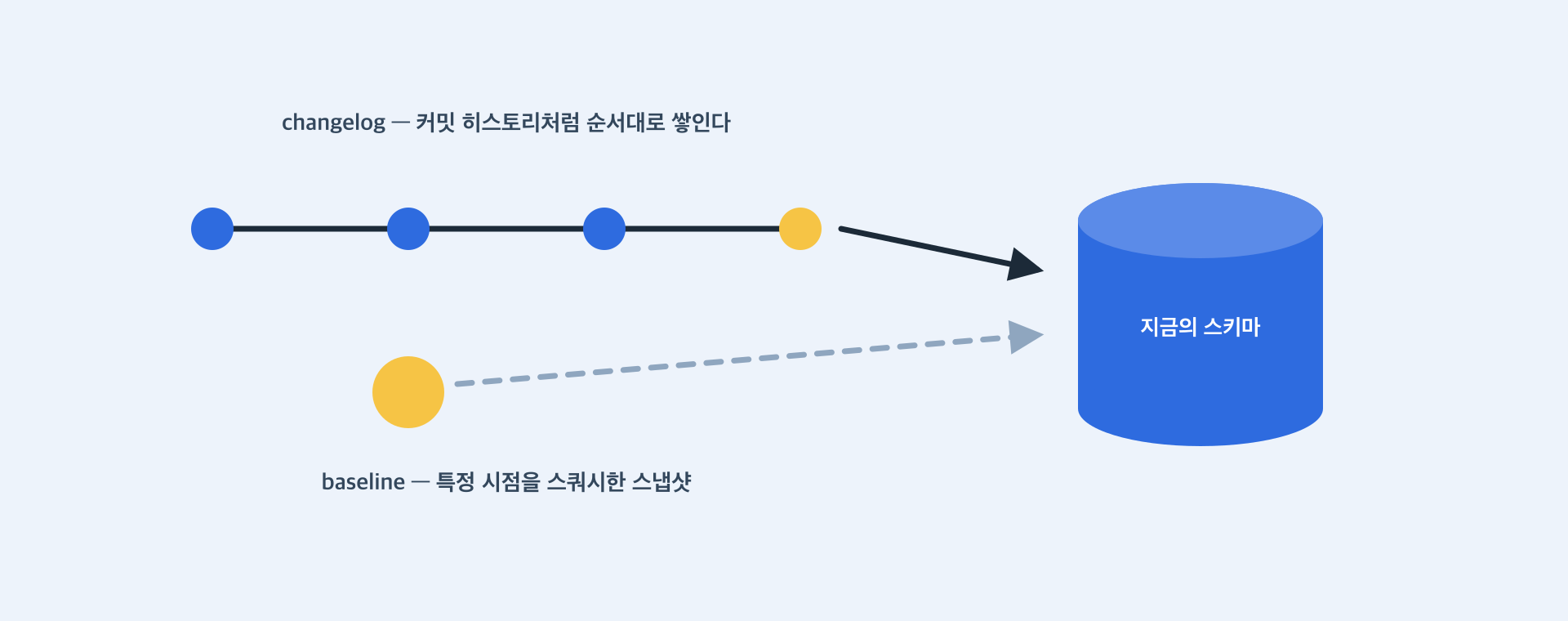
- changelog(체인지셋) — 증분 변경 SQL입니다. 파일로 레포에 커밋되고, 도구가 순서대로 적용하며, 이미 적용된 것은 건너뜁니다. git의 커밋 히스토리입니다.
- baseline — 특정 시점의 스키마 전체 스냅샷입니다. 새 환경을 처음부터 체인지셋 수백 개로 쌓지 않고 빠르게 초기화하는 용도입니다. 스쿼시된 초기 커밋입니다.
컬럼 추가는 그래서 DB 콘솔이 아니라 코드 리뷰를 받는 SQL 파일이 됩니다.
-- changelog — 증분 변경만 쌓는다. 순서대로 적용되고, 적용된 것은 건너뛴다
ALTER TABLE user_profile ADD COLUMN military JSON NULL;
그리고 서두에서 고백한 CI 사고가 여기서 나옵니다. 새 컬럼을 changelog에 적고, "완전성"을 위한답시고 baseline 스냅샷에도 손으로 추가했습니다. 그 결과 baseline으로 초기화한 뒤 changelog를 적용하는 테스트 환경에서 같은 컬럼이 두 번 추가되며 Duplicate column 에러로 무너졌습니다. git으로 번역하면 정확히 이해가 됩니다 — 이미 스쿼시된 과거 커밋을 손으로 고쳐놓고, 같은 변경을 새 커밋으로 또 쌓은 것입니다. 신규 변경은 changelog에만 적고 baseline은 도구가 갱신하게 둔다, 가 규칙이었습니다.
Recap
마이그레이션 도구는 DB용 git입니다 — changelog는 순서대로 적용되는 커밋 히스토리, baseline은 빠른 초기화를 위한 스쿼시 스냅샷입니다. 신규 변경은 changelog에만 적어야 하며, baseline까지 손으로 고치면 같은 변경이 두 번 적용되어 무너집니다.
3. 변경 이력은 자동으로 남깁니다
스키마의 역사가 changelog에 남는다면, 데이터의 역사는 어디에 남을까요. 개인정보나 급여처럼 민감한 도메인에는 "누가 언제 무엇을 바꿨는가"를 답해야 하는 감사(audit) 요구가 따라붙습니다.
이걸 매번 손으로 기록하는 대신 자동화하는 장치가 있습니다. JPA 진영에서는 Hibernate Envers가 대표적입니다 — 엔티티에 어노테이션 하나를 붙이면 변경분이 별도의 *_audit 테이블에 자동으로 쌓입니다.
@Audited // 변경분이 user_profile_audit 테이블에 자동 적재된다 — 누가, 언제, 무엇을
@Entity
class UserProfileEntity(/* ... */)
클래스 레벨에 이미 @Audited가 붙어 있는 엔티티라면, 새 컬럼을 추가할 때 audit 테이블에도 같은 컬럼을 추가하는 체인지셋 하나만 따라가면 이력은 공짜로 얻습니다. 프론트엔드로 억지로 비유하면 상태 변경마다 자동으로 쌓이는 undo/history 로그인데, 되돌리기 위해서가 아니라 답하기 위해 존재한다는 점이 다릅니다 — "이 값 왜 바뀌었어요?"라는 질문에 테이블이 대신 답해 줍니다.
이것으로 데이터 이야기까지 끝났습니다. 남은 것은 하나 — 이 여정 내내 스쳐 지나간 백엔드 도구들을 한 바퀴 돌며 FE 대응물로 정리하는 일입니다. 시리즈의 마지막 글에서 하겠습니다.
Recap
스키마의 역사가 changelog에 남듯 데이터의 역사는 audit 테이블에 남습니다. Envers 같은 도구는 어노테이션 하나로 변경분을 자동 적재하며, 엔티티에 컬럼을 추가할 때 audit 테이블 체인지셋만 따라가면 "누가 언제 무엇을 바꿨는가"에 답할 수 있는 이력이 공짜로 쌓입니다.
FE ↔ BE 대응표
이 글에서 다룬 대응입니다.
| BE 개념 | FE에서 가장 가까운 것 | 대응의 핵심 |
|---|---|---|
| 스키마 마이그레이션 | (대응물 없음) | 살아남는 데이터를 새 구조로 옮기는 일 |
| changelog / baseline | 커밋 히스토리 / 스쿼시 | DB용 git |
| audit 테이블 (Envers) | undo/history 로그 | 되돌리기가 아니라 답하기 위한 이력 |
References
진화하는 데이터베이스
도구