그 로직은 어디에 살아야 할까요?
이 글은 직무 통합 과정에서 백엔드 실무를 맡게 된 프론트엔드 개발자가 실제 작업을 부딪히며 배운 것들을 주제 단위로 정리하는 시리즈입니다. 낯선 개념을 이미 아는 개념에 대응시키는 방식으로 씁니다.
첫 검증 로직을 쓰다가 한참을 멈춰 있었습니다. "복무 기간은 군필이거나 복무 중일 때만 의미가 있다"는 규칙 하나 — 이걸 모델에 둘까, 서비스에 둘까, 컨트롤러에서 걸러낼까. 사실 프론트엔드에서도 같은 고민을 매일 했습니다. 이 계산은 컴포넌트에 둘까, 훅에 둘까, util에 둘까. 다만 백엔드는 이 질문에 대한 오래된 어휘와 지도를 갖고 있었습니다.
어떤 로직이 모델에 살고, 어떤 로직이 서비스에 살아야 할까요?
이 글에서 다루는 내용
지난 글까지가 구조와 방향의 이야기였다면 이번에는 그 구조 안에서 코드의 주소를 정하는 이야기입니다. 모델 안에 로직을 얼마나 둘 것인지(rich vs anemic), 서비스가 왜 두 종류로 나뉘는지(도메인 서비스 vs 애플리케이션 서비스), 그리고 권한 검사는 왜 모델에 살지 않는지를 다룹니다. 이번에도 순수 도메인 util, 오케스트레이션 훅, 라우트 가드라는 익숙한 대응물이 그대로 등장합니다.
1. 모델 안의 로직, rich와 anemic
모델이 순수하다는 것까지는 정리가 됐는데, 그 순수한 모델 안에 로직을 얼마나 둘 것인가는 별개의 질문입니다. 여기에는 두 학파가 있습니다.
- Anemic(빈약한) 도메인 모델 — 모델은 필드만 가진 데이터 봉투고 로직은 전부 서비스에 삽니다. Martin Fowler가 안티패턴이라고 이름 붙인 쪽이지만, 단순 CRUD 도메인에서는 실용적이라는 반론도 만만치 않습니다.
- Rich(풍부한) 도메인 모델 — 자기 데이터에 대한 규칙은 자기가 갖습니다. "엑셀을 밟으면 출발한다"가 자동차 모델 안에 있는 것입니다. 검증(validate)·정규화(normalize) 메서드가 모델에 붙습니다.
서두의 병역 규칙을 rich 스타일로 쓰면 이렇게 됩니다. 규칙이 데이터와 같은 집에 삽니다.
// 값객체 — 자기 데이터의 정합성 규칙을 자기가 안다
data class MilitaryService(
val status: MilitaryStatus = MilitaryStatus.UNKNOWN,
val type: MilitaryType = MilitaryType.UNKNOWN,
val startDate: LocalDate? = null,
val endDate: LocalDate? = null,
) {
// 복무 종류와 기간은 군필/복무중일 때만 의미가 있다.
// 다른 상태로 바뀌면 남아 있는 값을 지운다
fun normalized(): MilitaryService =
if (status == MilitaryStatus.COMPLETED || status == MilitaryStatus.IN_SERVICE) this
else copy(type = MilitaryType.UNKNOWN, startDate = null, endDate = null)
}
이 규칙을 모델 밖의 검증 서비스에 두면 anemic 쪽으로 한 칸 이동한 것입니다. 어느 쪽이 정답이냐고 물으면 돌아오는 대답은 한결같았습니다 — 정답이 아니라 스펙트럼이고, 팀마다 레포마다 앉는 위치가 다르다.
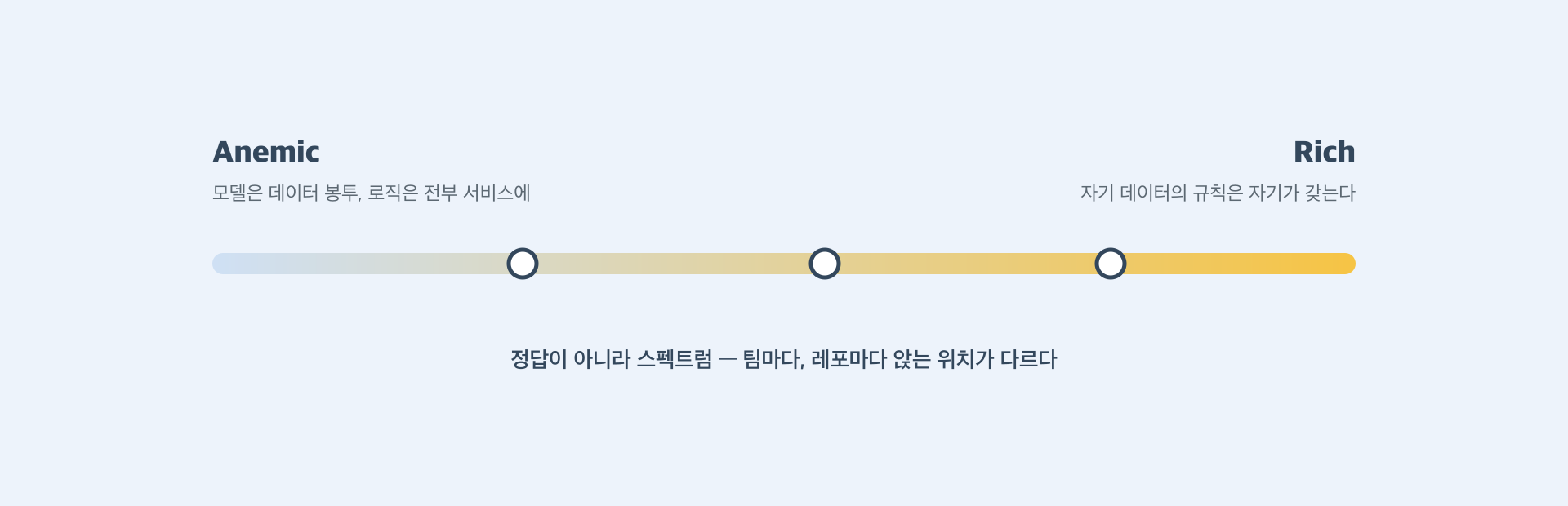
프론트엔드로 번역하면 이 스펙트럼은 plain object + 흩어진 util 함수들과 메서드를 가진 도메인 객체 사이의 선택입니다. 폼 라이브러리에 밸리데이터를 따로 등록하는 방식이 anemic 쪽이라면, 폼 모델이 .validate()를 갖는 방식이 rich 쪽입니다. 파서 함수 하나에 정합성 규칙을 모아두는 방식도 이 스펙트럼 위의 한 지점입니다. 우리는 이미 매일 이 선택을 하고 있었고, 다만 그 축에 이름이 있는 줄 몰랐을 뿐입니다.
Recap
모델 안에 로직을 얼마나 둘 것인가에는 anemic(데이터 봉투 + 서비스 로직)과 rich(자기 규칙은 자기가) 두 학파가 있고, 정답이 아니라 스펙트럼입니다. 프론트엔드의 plain object + util vs 메서드를 가진 도메인 객체와 같은 축이며, 팀과 레포마다 앉는 위치가 다르다는 것을 받아들이는 것이 시작입니다.
2. 서비스는 두 종류입니다
"로직은 서비스에"라고 말할 때의 서비스가 사실 한 종류가 아니라는 것이 이번 온보딩에서 배운 가장 유용한 구분이었습니다.
- 도메인 서비스(domain service) — 특정 엔티티 하나에 자연스럽게 귀속되지 않는 도메인 로직입니다. 교과서 예시는 두 계좌 사이의 이체 규칙입니다. 출금 계좌의 메서드로 두기도, 입금 계좌의 메서드로 두기도 애매한 규칙이라 별도의 서비스가 됩니다. 무상태이고 업무 언어로 이름이 지어집니다.
- 애플리케이션 서비스(application service) — 도메인 로직을 갖지 않습니다. 트랜잭션 경계, 권한 확인, 도메인 객체와 리포지토리를 부르는 순서, 다른 도메인 호출의 조율 — 오케스트레이션이 전부입니다. 지난 글들의 "유즈케이스"가 대체로 이 층입니다.
// 애플리케이션 서비스 — 도메인 로직 없이 흐름만 지휘한다
class UpdateUserProfile(
private val repository: UserProfileRepository,
private val permissionChecker: PermissionChecker,
) {
@Transactional
fun execute(actorId: UserId, command: UpdateProfileCommand) {
permissionChecker.check(actorId, MANAGE_PROFILE) // 권한
val profile = repository.find(command.userId) ?: throw ProfileNotFound()
profile.update(command.changes) // 규칙은 모델에 위임한다
repository.save(profile) // 순서와 트랜잭션만 책임진다
}
}
둘을 가르는 판별 질문이 있습니다.
"이 로직을 트랜잭션·권한·API 같은 기술 용어 없이, 업무 언어만으로 설명할 수 있는가?"
설명이 되면 도메인 서비스, 안 되면 애플리케이션 서비스입니다.
프론트엔드 대응은 이렇습니다. 도메인 서비스는 순수 도메인 util — calculateProrated(salary, days)처럼 React도 API도 모르는 함수입니다. 애플리케이션 서비스는 컨테이너·오케스트레이션 훅 — 데이터 페칭과 권한 체크와 뮤테이션과 라우팅을 조합하되 로직 자체는 아래에 위임하고 흐름만 지휘하는 층입니다. 훅이 비대해질 때 "이 계산은 순수 함수로 뽑자"라고 하던 그 감각이, 백엔드에서는 "이건 도메인 서비스로 내리자"가 됩니다.
Recap
서비스는 두 종류입니다. 도메인 서비스는 한 엔티티에 담기 애매한 도메인 규칙(계좌 이체)이고, 애플리케이션 서비스는 도메인 로직 없이 트랜잭션·권한·호출 순서를 지휘하는 오케스트레이션입니다. 판별 질문은 "기술 용어 없이 업무 언어만으로 설명되는가"이고, 프론트엔드의 순수 도메인 util과 오케스트레이션 훅에 각각 대응합니다.
3. 모델은 페르소나를 모릅니다
위의 애플리케이션 서비스 코드에서 권한 확인이 첫 줄에 있었습니다. 이것은 우연이 아닙니다. 인가(authorization)는 애플리케이션의 관심사입니다. 모델은 "병역이 무엇인가"만 알고 "누가 볼 수 있는가"는 모릅니다.
이 원칙이 고마워지는 순간은 페르소나가 늘어날 때입니다. 평가 도메인처럼 보는 사람이 많은 곳 — 평가자, 피평가자, 관리자 — 을 상상해 보면, 페르소나별로 보이는 것이 달라도 모델은 하나로 그대로입니다. 차이는 전부 모델 바깥, API와 애플리케이션 서비스에서 표현됩니다. 조회 응답에서 권한 없는 필드를 서버가 지워서 내려주는 필드 단위 마스킹도 같은 층의 일입니다.
// 애플리케이션 레이어 — 권한이 없으면 민감 필드를 빈값으로 교체해 내려준다
val masked =
if (canViewSensitive(actor)) profile
else profile.copy(military = MilitaryService()) // 모델은 이 사정을 모른다
프론트엔드에서는 이미 이렇게 살고 있습니다. 프레젠테이션 컴포넌트는 권한을 모르고 라우트 가드와 컨테이너가 압니다. 권한 훅을 컴포넌트 트리 위쪽에서 처리하고 아래는 순수하게 두는 그 원칙이, 백엔드에서는 "권한은 애플리케이션 레이어에, 모델은 순수하게"가 됩니다.
한 가지는 짚고 가겠습니다. 모든 접근 규칙이 애플리케이션 관심사인 것은 아닙니다. "작성자만 수정할 수 있다"처럼 업무 규칙에 가까운 인가는 도메인 쪽으로 끌어올 수도 있습니다. 여기서 말하는 것은 페르소나별 노출 제어 — 누가 어느 필드를 보는가 — 이고, 이런 것일수록 모델 밖이 제자리라는 것입니다.
그런데 "권한을 어디에 거는가"를 한 층 더 밀고 나가면 API 자체의 종류 이야기가 됩니다. 고객이 부르는 API와 어드민이 부르는 API, 그리고 다른 서버가 부르는 API는 권한을 다르게 답니다 — 다음 글에서 다루겠습니다.
Recap
인가는 애플리케이션의 관심사입니다. 모델은 개념만 알고 누가 볼 수 있는지는 모르기 때문에, 페르소나가 늘어나도 모델은 하나로 유지되고 차이는 API·애플리케이션 서비스에서 표현됩니다. 프레젠테이션 컴포넌트를 권한에서 자유롭게 두고 라우트 가드가 막는 프론트엔드의 원칙과 같은 결이며, 다만 "작성자만 수정"처럼 업무 규칙에 가까운 인가는 예외적으로 도메인 쪽에 살 수 있습니다.
FE ↔ BE 대응표
이 글에서 다룬 대응입니다. 1편·2편의 표에 이어집니다.
| BE 개념 | FE에서 가장 가까운 것 | 대응의 핵심 |
|---|---|---|
| rich 도메인 모델 | 메서드를 가진 도메인 객체 | 자기 데이터의 규칙은 자기가 |
| anemic 모델 + 서비스 | plain object + util 함수들 | 데이터와 로직의 분리 |
| 도메인 서비스 | 순수 도메인 util | 프레임워크를 모르는 업무 규칙 |
| 애플리케이션 서비스 | 컨테이너 · 오케스트레이션 훅 | 조율만 하고 로직은 위임 |
| 인가의 자리 | 라우트 가드 · 권한 훅 | 모델 밖, 흐름의 관문에서 |
References
도메인 모델과 로직의 자리
서비스 레이어